Cátedra 2
- Compilación
- Depuración
- help50 y printf
- debug50
- check50 y style50
- Tipos de datos
- Memoria
- Matrices
- Cadenas
- Argumentos de línea de comandos
- Legibilidad
- Encriptación
Compilación
- La última vez aprendimos a escribir nuestro primer programa en C. Aprendimos la sintaxis para la función
mainen nuestro programa, la funciónprintfpara imprimir en el terminal, cómo crear cadenas con comillas dobles y cómo incluirstdio.hpara la funciónprintf. - Luego, lo compilamos con
clang hello.cpara poder ejecutar./a.out(el nombre predeterminado), y luegoclang -o hello hello.c(pasando un argumento de línea de comandos para el nombre de salida) para poder ejecutar./hello. - Si quisiéramos usar la biblioteca de CS50, a través de
#include <cs50.h>, para cadenas y la funciónget_string, también tenemos que agregar un indicador:clang -o hello hello.c -lcs50. El indicador-lvincula el archivocs50, que ya está instalado en CS50 Sandbox, e incluye prototipos o definiciones de cadenas yget_string(entre otros) a los que nuestro programa puede referirse y usar. - Escribimos nuestro código fuente en C, pero necesitamos compilarlo a código máquina, en binario, antes de que nuestras computadoras puedan ejecutarlo.
clanges el compilador ymakees una utilidad que nos ayuda a ejecutarclangsin tener que indicar todas las opciones manualmente.
- La "compilación" del código fuente en código máquina en realidad se compone de pasos más pequeños:
- Preprocesamiento
- Compilación
- Ensamblado
- Vinculación
- El preprocesamiento implica mirar las líneas que comienzan con un símbolo
#, como#include, antes que cualquier otra cosa. Por ejemplo,#include <cs50.h>le indicará aclangque primero busque ese archivo de encabezado, ya que contiene contenido que queremos incluir en nuestro programa. Luego,clangesencialmente reemplazará el contenido de esos archivos de encabezado en nuestro programa. -
Por ejemplo...
#include <cs50.h> #include <stdio.h> int main(void) { string name = get_string("Name: "); printf("hello, %s\n", name); } -
... se preprocesará en:
string get_string(string prompt); int printf(const char *format, ...); int main(void) { string name = get_string("Name: "); printf("hello, %s\n", name); } -
La compilación toma nuestro código fuente, en C, y lo convierte en código ensamblador, que se ve así:
... main: # @main .cfi_startproc # BB#0: pushq %rbp .Ltmp0: .cfi_def_cfa_offset 16 .Ltmp1: .cfi_offset %rbp, -16 movq %rsp, %rbp .Ltmp2: .cfi_def_cfa_register %rbp subq $16, %rsp xorl %eax, %eax movl %eax, %edi movabsq $.L.str, %rsi movb $0, %al callq get_string movabsq $.L.str.1, %rdi movq %rax, -8(%rbp) movq -8(%rbp), %rsi movb $0, %al callq printf ...- Estas instrucciones son de un nivel inferior y más cercanas a las instrucciones binarias que la CPU de una computadora puede entender directamente. Generalmente operan en bytes mismos, en contraposición a abstracciones como nombres de variables.
-
El siguiente paso es tomar el código ensamblador y traducirlo a instrucciones en binario ensamblándolo. Las instrucciones en binario se denominan código máquina, que la CPU de una computadora puede ejecutar directamente.
- El último paso es vincular, donde el contenido de las bibliotecas previamente compiladas que queremos vincular, como
cs50.c, se combinan realmente con el binario de nuestro programa. Por lo tanto, terminamos con un archivo binario,a.outohello, que es la versión compilada dehello.c,cs50.cyprintf.c.
Depuración
- Los errores son equivocaciones en programas que no teníamos intención de cometer. Y la depuración es el proceso de encontrar y corregir errores.
help50 y printf
-
Digamos que escribimos este programa,
buggy0.c:int main(void) { printf("hello, world\n"); } -
Vemos un error (en rojo), cuando intentamos compilar este programa, de que estamos "declarando implícitamente la función de biblioteca 'printf'". Realmente no entendemos esto, por lo que podemos ejecutar
help50 make buggy0, que nos dirá, al final, que podríamos habernos olvidado de escribir#include <stdio.h>, que contieneprintf. -
Podemos intentarlo de nuevo con
buggy1.c:#include <stdio.h> int main(void) { string name = get_string("What's your name?\n"); printf("hello, %s\n", name); } -
Vemos muchos errores, e incluso el primero no parece tener mucho sentido. Entonces, podemos ejecutar de nuevo
help50 make buggy1, que nos indicará que necesitamoscs50.hya questringno está definida. -
Para borrar la ventana del terminal (para que podamos ver solo la salida de lo que queremos ejecutar a continuación), podemos presionar
control + L, o escribirclearcomo un comando en la ventana del terminal. -
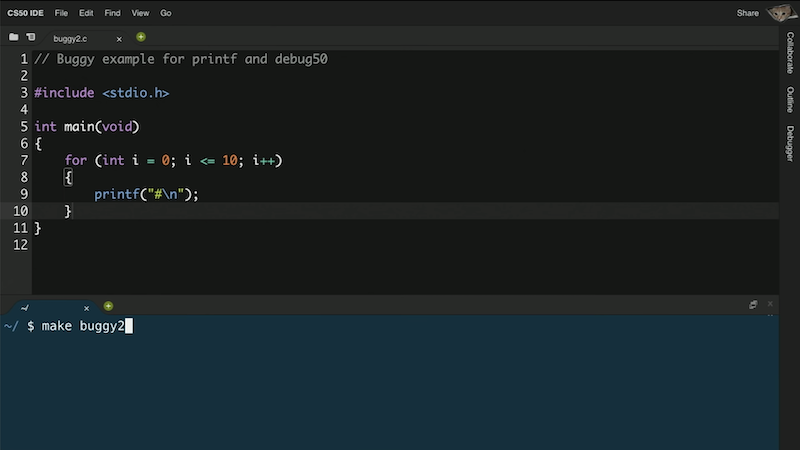
Veamos
buggy2.c:#include <stdio.h> int main(void) { for (int i = 0; i <= 10; i++) { printf("#\n"); } } -
Mmm, pretendíamos ver solo 10
#, pero hay 11. Si no supiéramos cuál es el problema (ya que nuestro programa se está compilando sin errores y ahora tenemos un error lógico), podríamos agregar otra línea de impresión para ayudarnos:#include <stdio.h> int main(void) { for (int i = 0; i <= 10; i++) { printf("i es ahora %i: ", i); printf("#\n"); } } -
Ahora, vemos que
icomenzó en 0 y continuó hasta que fue 10, pero deberíamos hacer que se detenga una vez que esté en 10, coni < 10en lugar dei <= 10.
debug50
- Hoy también veremos el IDE CS50, que es como el Sandbox CS50 pero con más funciones. Es un entorno de desarrollo en línea con un editor de código y una ventana de terminal pero también con herramientas para depuración y colaboración.
- En el IDE CS50 tendremos otra herramienta,
debug50, para ayudarnos a depurar programas. - Abriremos
buggy2.ce intentaremosmake buggy2. Pero guardamosbuggy2.cen una carpeta llamadasrc2, así que necesitamos ejecutarcd src2para cambiar nuestro directorio al correcto. Y la terminal del IDE CS50 nos recordará en qué directorio estamos, con un indicador como~/src/ $. (El~indica el directorio predeterminado o de inicio). - En lugar de usar
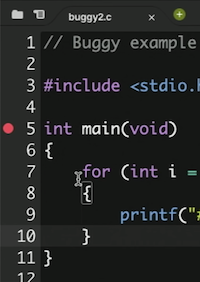
printf, también podemos depurar nuestro programa de forma interactiva. Podemos agregar un punto de interrupción o un indicador para una línea de código donde el depurador debe pausar nuestro programa. Por ejemplo, podemos hacer clic a la izquierda de la línea 5 de nuestro código y aparecerá un círculo rojo:
- Ahora, si ejecutamos
debug50 ./buggy2, veremos que el panel del depurador se abre a la derecha:
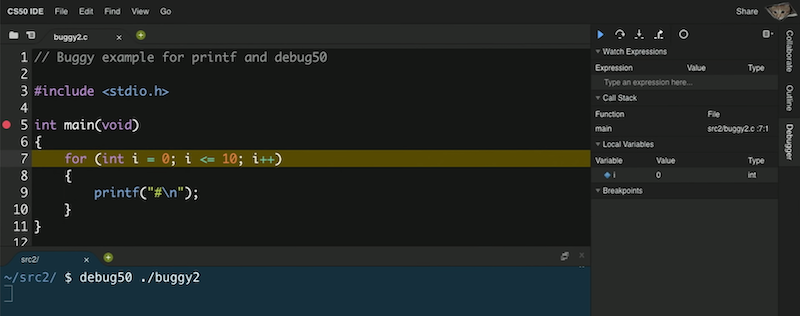
- Vemos que la variable que creamos,
i, se encuentra en la secciónVariables localesy vemos que tiene un valor de0. - Nuestro punto de interrupción ha pausado nuestro programa después de la línea 5, justo antes de la línea 7, ya que es la primera línea de código que puede ejecutarse. Para continuar, tenemos algunos controles en el panel del depurador. El triángulo azul continuará nuestro programa hasta que lleguemos a otro punto de interrupción o al final de nuestro programa. La flecha curva a su derecha "pasará por encima" de la línea, ejecutándola y pausando nuestro programa nuevamente inmediatamente después.
- Por lo tanto, usaremos la flecha curva para ejecutar la siguiente línea y ver qué cambios después. Estamos en la línea
printfy, al presionar la flecha curva nuevamente, vemos un solo#impreso en nuestra ventana de terminal. Con otro clic de la flecha, vemos que el valor deia la derecha cambia a1. Y podemos seguir haciendo clic en la flecha para ver cómo se ejecuta nuestro programa, una línea a la vez. - Para salir del depurador, podemos presionar
control + Cpara detener el programa. - ¡Podemos ahorrar mucho tiempo en el futuro si invertimos un poco ahora para aprender a usar
debug50!
check50 y style50
- Podemos ejecutar un comando como
check50 cs50/problems/hello, dondecheck50es un programa que seguirá las instrucciones identificadas por el argumentocs50/problems/hellopara cargar, ejecutar y probar nuestro programa en los servidores de CS50. Esto verificará que nuestro programa sea correcto.- Al escribir software en el mundo real, los desarrolladores generalmente escribirán sus propias pruebas para asegurarse de que su código funcione como esperan, especialmente a medida que se agregan más funciones al mismo código.
style50es otro programa que verificará nuestro código en busca de problemas estéticos, como espacios en blanco, de modo que nuestro código sea más legible y fácil de mantener. Por ejemplo, podríamos estar perdiendo sangría. Y Style Guide incluirá más explicaciones sobre lo que esperamos.- Incluso podemos utilizar la depuración del pato de goma, un método en el que explicamos lo que estamos tratando de hacer a un pato de goma, de modo que nos demos cuenta de lo que estamos tratando de hacer y lo que debemos solucionar.
- También queremos escribir nuestro código con un buen diseño, donde no solo resolvemos el problema correctamente sino también bien, donde tomamos decisiones razonables sobre cómo se ejecuta nuestro programa y hacemos concesiones entre tiempo, costo de desarrollo y memoria.
Tipos de datos
- En C, tenemos diferentes tipos de variables que podemos usar para almacenar datos:
- bool 1 byte
- char 1 byte
- int 4 bytes
- float 4 bytes
- long 8 bytes
- double 8 bytes
- string ? bytes
- Cada uno de estos tipos ocupa una cierta cantidad de bytes por variable que creamos, y los tamaños anteriores son los que utilizan la zona temporal, el IDE y probablemente el equipo para cada tipo en C.
Memoria
- Dentro de nuestras computadoras, tenemos chips llamados RAM, memoria de acceso aleatorio, que almacena datos para uso a corto plazo. Podemos guardar un programa o archivo en nuestro disco duro (o SSD) para almacenamiento a largo plazo, pero cuando lo abrimos, primero se copia en la RAM. Aunque la RAM es mucho más pequeña y temporal (hasta que se apaga la alimentación), es mucho más rápida.
- Podemos pensar en bytes, almacenados en RAM, como si estuvieran en una cuadrícula:

- En realidad, hay millones o miles de millones de bytes por chip.
- En C, cuando creamos una variable de tipo "char", que tendrá un tamaño de un byte, se almacenará físicamente en una de esas casillas en la RAM. Un entero, con 4 bytes, ocupará cuatro de esas casillas.
- Y cada una de estas casillas está etiquetada con algún número o dirección, de 0 a 1, a 2, etc.
Arreglos
-
Digamos que queremos almacenar tres variables:
#include <stdio.h> int main(void) { char c1 = 'H'; char c2 = 'I'; char c3 = '!'; printf("%c %c %c\n", c1, c2, c3); }- Observa que usamos comillas simples para indicar un carácter literal y comillas dobles para agrupar múltiples caracteres en una cadena.
- Podemos compilar y ejecutar esto para ver
H I !.
-
Y sabemos que los caracteres son solo números, así que si cambiamos el formato de nuestra cadena a
printf("%i %i %i\n", c1, c2, c3);, podemos ver los valores numéricos de cada carácter impreso:72 73 33.- Podemos convertir explícitamente, o convertir el tipo, de cada carácter a un int antes de usarlo, con
(int) c1, pero nuestro compilador puede hacerlo implícitamente por nosotros.
- Podemos convertir explícitamente, o convertir el tipo, de cada carácter a un int antes de usarlo, con
- Y en memoria, podríamos tener tres cajas, etiquetadas como
c1,c2yc3de alguna manera, cada una de las cuales representa un byte binario con los valores de cada variable. -
Veamos
scores0.c:#include <cs50.h> #include <stdio.h> int main(void) { // Puntuaciones int score1 = 72; int score2 = 73; int score3 = 33; // Imprimir promedio printf("Promedio: %i\n", (score1 + score2 + score3) / 3); }- Podemos imprimir el promedio de tres números, pero ahora necesitamos crear una variable para cada puntuación que queramos incluir, y no podemos usarlas fácilmente más tarde.
-
Resulta que, en memoria, podemos almacenar variables una tras otra, una al lado de la otra. Y en C, una lista de variables almacenadas, una tras otra en un fragmento contiguo de memoria, se llama arreglo.
- Por ejemplo, podemos usar
int scores[3];para declarar un arreglo de 3 enteros. -
Y podemos asignar y usar variables en un arreglo con:
#include <cs50.h> #include <stdio.h> int main(void) { // Puntuaciones int scores[3]; scores[0] = 72; scores[1] = 73; scores[2] = 33; // Imprimir promedio printf("Promedio: %i\n", (scores[0] + scores[1] + scores[2]) / 3); }- Observa que los arreglos tienen índice cero, lo que significa que el primer elemento, o valor, tiene índice 0.
-
Y repetimos el valor 3, que representa la longitud de nuestro arreglo, en dos lugares diferentes. Entonces podemos usar una constante, o valor fijo, para indicar que siempre debe ser el mismo en ambos lugares:
#include <cs50.h> #include <stdio.h> const int N = 3; int main(void) { // Puntuaciones int scores[N]; scores[0] = 72; scores[1] = 73; scores[2] = 33; // Imprimir promedio printf("Promedio: %i\n", (scores[0] + scores[1] + scores[2]) / N); }- Podemos usar la palabra clave
constpara decirle al compilador que el valor deNnunca debe ser cambiado por nuestro programa. Y por convención, colocaremos nuestra declaración de la variable fuera de la funciónmainy pondremos su nombre en mayúsculas, lo cual no es necesario para el compilador pero muestra a otros humanos que esta variable es una constante y la hace fácil de ver desde el principio.
- Podemos usar la palabra clave
-
Con un arreglo, podemos recopilar nuestras puntuaciones en un ciclo y también acceder a ellas más tarde en un ciclo:
#include <cs50.h> #include <stdio.h> float average(int length, int array[]); int main(void) { // Obtener el número de puntuaciones int n = get_int("Puntuaciones: "); // Obtener puntuaciones int scores[n]; for (int i = 0; i < n; i++) { scores[i] = get_int("Puntuación %i: ", i + 1); } // Imprimir promedio printf("Promedio: %.1f\n", average(n, scores)); } float average(int length, int array[]) { int sum = 0; for (int i = 0; i < length; i++) { sum += array[i]; } return (float) sum / (float) length; }- Primero, le pediremos al usuario el número de puntuaciones que tiene, crearemos un arreglo con suficientes
intpara el número de puntuaciones que tiene y usaremos un ciclo para recopilar todas las puntuaciones. - Luego escribiremos una función auxiliar,
average, para devolver unfloat, o un valor decimal. Pasaremos la longitud y un arreglo deint(que podría ser de cualquier tamaño), y usaremos otro ciclo dentro de nuestra función auxiliar para sumar los valores en una suma. Usamos(float)para convertirsumylengthen flotantes, por lo que el resultado que obtenemos al dividir los dos también es un flotante. - Finalmente, cuando imprimimos el resultado que obtenemos, usamos
%.1fpara mostrar solo un lugar después del decimal.
- Primero, le pediremos al usuario el número de puntuaciones que tiene, crearemos un arreglo con suficientes
-
En memoria, nuestro arreglo ahora se almacena de esta manera, donde cada valor ocupa no uno sino cuatro bytes:

Cadenas
- Las cadenas son en realidad matrices de caracteres. Si tuviéramos una cadena
s, a cada carácter se puede acceder cons[0],s[1], etc. - Y resulta que una cadena termina con un carácter especial, ‘\0’, o un byte con todos los bits configurados a 0. Este carácter se llama carácter nulo o carácter de terminación nulo. Entonces, en realidad necesitamos cuatro bytes para almacenar nuestra cadena “¡HOLA!”:
![rejilla con H etiquetada como s[0], I etiquetada como s[1], ! etiquetada como s[2], \0 etiquetada como s[3], cada una de las cuales ocupa un cuadro, y muchos cuadros vacíos a continuación](https://cs50.harvard.edu/x/2020/notes/2/memory_with_string.png)
-
Ahora veamos cómo podrían verse cuatro cadenas en una matriz:
string nombres[4]; nombres[0] = "EMMA"; nombres[1] = "RODRIGO"; nombres[2] = "BRIAN"; nombres[3] = "DAVID"; printf("%s\n", nombres[0]); printf("%c%c%c%c\n", nombres[0][0], nombres[0][1], nombres[0][2], nombres[0][3]);- Podemos imprimir el primer valor en
nombrescomo una cadena, o podemos obtener la primera cadena y obtener cada carácter individual en esa cadena usando[]nuevamente. (Podemos pensarlo como(nombres[0])[0], aunque no necesitamos los paréntesis). - Y aunque sabemos que el primer nombre tenía cuatro caracteres,
printfprobablemente usó un bucle para mirar cada carácter de la cadena, imprimiéndolos uno a la vez hasta que llegó al carácter nulo que marca el final de la cadena. Y de hecho, podemos imprimirnombres[0][4]como unintcon%iy ver que se imprime un0.
- Podemos imprimir el primer valor en
-
Podemos visualizar cada carácter con su propia etiqueta en la memoria:
![rejilla con E etiquetada como nombres[0][0], M etiquetada como nombres[0][1], y así sucesivamente, hasta nombres[3][5] con un \0, cada uno de los cuales ocupa un cuadro y cuadros vacíos a continuación](https://cs50.harvard.edu/x/2020/notes/2/memory_with_string_array.png)
-
Podemos intentar experimentar con
string0.c:#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Entrada: "); printf("Salida: "); for (int i = 0; i < strlen(s); i++) { printf("%c", s[i]); } printf("\n"); }- Podemos usar la condición
s[i] != '\0', donde podemos verificar el carácter actual y solo imprimirlo si no es el carácter nulo. - También podemos usar la longitud de la cadena, pero primero, necesitamos una nueva biblioteca,
string.h, parastrlen, que nos dice la longitud de una cadena.
- Podemos usar la condición
-
Podemos mejorar el diseño de nuestro programa.
string0fue un poco ineficiente, ya que comprobamos la longitud de la cadena, después de imprimir cada carácter, en nuestra condición. Pero como la longitud de la cadena no cambia, podemos comprobar la longitud de la cadena una vez:#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Entrada: "); printf("Salida:\n"); for (int i = 0, n = strlen(s); i < n; i++) { printf("%c\n", s[i]); } }- Ahora, al inicio de nuestro bucle, inicializamos una variable
iyn, y recordamos la longitud de nuestra cadena enn. Luego, podemos verificar los valores cada vez, sin tener que calcular realmente la longitud de la cadena. - Y necesitábamos usar un poco más de memoria para
n, pero esto nos ahorra algo de tiempo al no tener que verificar la longitud de la cadena cada vez.
- Ahora, al inicio de nuestro bucle, inicializamos una variable
-
Ahora podemos combinar lo que hemos visto para escribir un programa que puede poner letras en mayúsculas:
#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Antes: "); printf("Después: "); for (int i = 0, n = strlen(s); i < n; i++) { if (s[i] >= 'a' && s[i] <= 'z') { printf("%c", s[i] - 32); } else { printf("%c", s[i]); } } printf("\n"); }- Primero, obtenemos una cadena
s. Luego, para cada carácter en la cadena, si es minúscula (su valor está entre el deayz), la convertimos en mayúscula. De lo contrario, simplemente la imprimimos. - Podemos convertir una letra minúscula a su equivalente en mayúsculas, restando la diferencia entre sus valores ASCII. (Sabemos que las letras minúsculas tienen un valor ASCII mayor que las letras mayúsculas, y la diferencia es convenientemente la misma entre las mismas letras, por lo que podemos restar esa diferencia para obtener una letra mayúscula de una letra minúscula).
- Primero, obtenemos una cadena
-
Podemos utilizar las páginas del manual (https://man.cs50.io/), o el manual del programador, para encontrar funciones de biblioteca que podamos utilizar para lograr lo mismo:
#include <cs50.h> #include <ctype.h> #include <stdio.h> #include <string.h> int main(void) { string s = get_string("Antes: "); printf("Después: "); for (int i = 0, n = strlen(s); i < n; i++) { printf("%c", toupper(s[i])); } printf("\n"); }- Al buscar en las páginas del manual, vemos que
toupper()es una función, entre otras, de una biblioteca llamadactype, que podemos utilizar.
- Al buscar en las páginas del manual, vemos que
Argumentos de línea de comando
- Hemos utilizado programas como
makeyclang, que reciben palabras adicionales después de su nombre en la línea de comando. Resulta que nuestros propios programas también pueden recibir argumentos de línea de comando. -
En
argv.c, cambiamos el aspecto de nuestra funciónmain:#include <cs50.h> #include <stdio.h> int main(int argc, string argv[]) { if (argc == 2) { printf("hola, %s\n", argv[1]); } else { printf("hola, mundo\n"); } } -
argcyargvson dos variables que nuestra funciónmainobtendrá ahora, cuando nuestro programa se ejecute desde la línea de comandos.argces el recuento de argumentos, o el número de argumentos, yargves un arreglo de cadenas que son los argumentos. Y el primer argumento,argv[0], es el nombre de nuestro programa (la primera palabra escrita, como./hello). En este ejemplo, verificamos si tenemos dos argumentos e imprimimos el segundo si es así. -
Por ejemplo, si ejecutamos
./argv David, obtendremoshola, Davidimpreso, ya que escribimosDavidcomo la segunda palabra en nuestro comando. -
Resulta que podemos indicar errores en nuestro programa devolviendo un valor desde nuestra función
main(como lo implica elintantes de nuestra funciónmain). De forma predeterminada, nuestra funciónmaindevuelve0para indicar que no hubo problemas, pero podemos escribir un programa para devolver un valor diferente:#include <cs50.h> #include <stdio.h> int main(int argc, string argv[]) { if (argc != 2) { printf("falta argumento de línea de comandos\n"); return 1; } printf("hola, %s\n", argv[1]); return 0; } -
El valor de retorno de
mainen nuestro programa se denomina código de salida. -
A medida que escribimos programas más complejos, códigos de error como este pueden ayudarnos a determinar qué salió mal, incluso si no es visible o significativo para el usuario.
Legibilidad
- Ahora que sabemos cómo trabajar con cadenas en nuestros programas, podemos analizar párrafos de texto para determinar su nivel de legibilidad, según factores como qué tan largas y complicadas son las palabras y oraciones.
Encriptación
- Si quisiéramos enviar un mensaje a alguien, podríamos querer encriptarlo, o codificarlo de alguna manera para que sea difícil de leer para otros. El mensaje original o la entrada a nuestro algoritmo se denomina texto sin formato y el mensaje encriptado o salida se denomina texto cifrado.
- Un mensaje como
HOLA!podría convertirse a ASCII:72 73 33. Pero cualquiera podría convertirlo de nuevo en letras. - Un algoritmo de encriptación generalmente requiere otra entrada, además del texto sin formato. Se necesita una clave y, a veces, es simplemente un número que se mantiene en secreto. Con la clave, el texto sin formato se puede convertir, mediante algún algoritmo, a texto cifrado y viceversa.
- Por ejemplo, si quisiéramos enviar un mensaje como
TE QUIERO, primero podemos convertirlo a ASCII:73 76 79 86 69 89 79 85. Luego, podemos encriptarlo con una clave de solo1y un algoritmo simple, en el que simplemente sumamos la clave a cada valor:74 77 80 87 70 90 80 86. Entonces, alguien que convierta ese ASCII de nuevo a texto veráU F P W G Z Q V. Para descifrar esto, alguien necesitará conocer la clave. - ¡Aplicaremos estos conceptos en nuestro conjunto de problemas!