Conferencia 4
- Hexadecimal
- Punteros
- cadena
- Comparar y copiar
- valgrind
- Intercambiar
- Distribución de memoria
- get_int
- Archivos
- JPEG
Hexadecimal
- En la semana 0, aprendimos sobre el sistema binario, un sistema de conteo con 0s y 1s.
- En la semana 2, hablamos sobre la memoria y cómo cada byte tiene una dirección, o identificador, para que podamos referirnos a dónde se almacenan realmente nuestras variables.
- Resulta que, por convención, las direcciones de memoria utilizan el sistema de conteo hexadecimal, donde hay 16 dígitos, del 0 al 9 y de la A a la F.
-
Recuerda que, en binario, cada dígito representaba una potencia de 2:
128 64 32 16 8 4 2 1 1 1 1 1 1 1 1 1- Con 8 bits, podemos contar hasta 255.
-
Resulta que, en hexadecimal, podemos contar perfectamente hasta 8 bits binarios con solo 2 dígitos:
16^1 16^0 F F- Aquí, el
Fes un valor de 15 en decimal, y cada lugar es una potencia de 16, por lo que el primerFes 16^1 _ 15 = 240, más el segundoFcon el valor de 16^0 _ 15 = 15, para un total de 255.
- Aquí, el
-
Y
0Aes lo mismo que 10 en decimal, y0Flo mismo que 15.10en hexadecimal sería 16, y lo diríamos como “uno cero en hexadecimal” en lugar de “diez”, si queremos evitar confusiones. - El sistema de colores RGB también usa convencionalmente hexadecimal para describir la cantidad de cada color. Por ejemplo,
000000en hexadecimal significa 0 de cada rojo, verde y azul, para un color negro. YFF0000sería 255, o la cantidad máxima posible, de rojo. Con diferentes valores para cada color, podemos representar millones de colores diferentes. - En la escritura, también podemos indicar que un valor está en hexadecimal prefijándolo con
0x, como en0x10, donde el valor es igual a 16 en decimal, a diferencia de 10.
Punteros
-
Podemos crear un valor
ne imprimirlo:#include <stdio.h> int main(void) { int n = 50; printf("%i\n", n); } -
Ahora tenemos 4 bytes en algún lugar de la memoria de nuestra computadora que contienen el valor binario de 50, etiquetado como
n:
- Resulta que, con los miles de millones de bytes en la memoria, esos bytes para la variable
ncomienzan en una dirección única que podría verse como0x12345678. -
En C, podemos ver la dirección con el operador
&, que significa "obtener la dirección de esta variable":#include <stdio.h> int main(void) { int n = 50; printf("%p\n", &n); }- Y en el IDE de CS50, podríamos ver una dirección como
0x7ffe00b3adbc, donde esta es una ubicación específica en la memoria del servidor.
- Y en el IDE de CS50, podríamos ver una dirección como
-
La dirección de una variable se llama puntero, que podemos considerar como un valor que "apunta" a una ubicación en la memoria. El operador
*nos permite "ir" a la ubicación a la que apunta un puntero. -
Por ejemplo, podemos imprimir
*&n, donde "vamos" a la dirección den, y eso imprimirá el valor den,50, ya que ese es el valor en la dirección den:#include <stdio.h> int main(void) { int n = 50; printf("%i\n", *&n); } -
También tenemos que usar el operador
*(de una manera desafortunadamente confusa) para declarar una variable que queremos que sea un puntero:#include <stdio.h> int main(void) { int n = 50; int *p = &n; printf("%p\n", p); }- Aquí, usamos
int *ppara declarar una variable,p, que tiene el tipo de*, un puntero, a un valor de tipoint, un entero. Luego, podemos imprimir su valor (algo como0x12345678) o imprimir el valor en su ubicación conprintf("%i\n", *p);.
- Aquí, usamos
-
En la memoria de nuestra computadora, las variables podrían verse así:
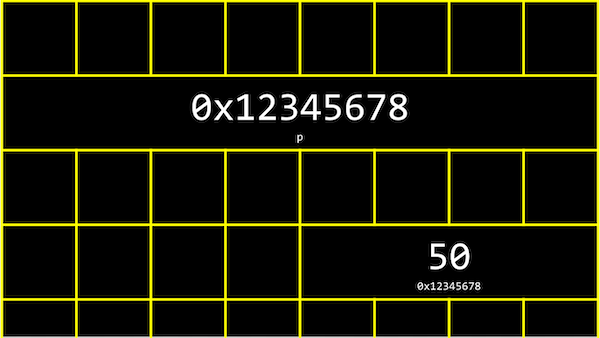
- Tenemos un puntero,
p, con la dirección de alguna variable.
- Tenemos un puntero,
- Ahora podemos abstraer el valor real de las direcciones, ya que serán diferentes a medida que declaramos variables en nuestros programas, y simplemente pensar en
pcomo "apuntando a" algún valor: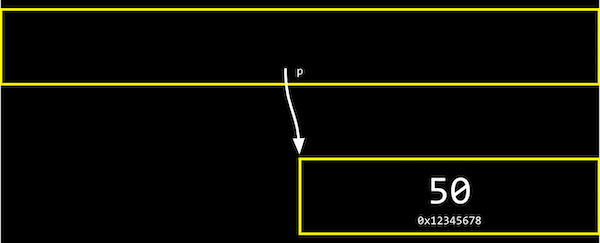
- Digamos que tenemos un buzón etiquetado como "123", con el número "50" dentro. El buzón sería
int n, ya que almacena un número entero. Podríamos tener otro buzón con la dirección "456", dentro del cual está el valor "123", que es la dirección de nuestro otro buzón. Esto seríaint *p, ya que es un puntero a un entero. - Con la capacidad de usar punteros, podemos crear diferentes estructuras de datos o diferentes formas de organizar datos en la memoria que veremos la próxima semana.
- Muchos sistemas informáticos modernos son "de 64 bits", lo que significa que utilizan 64 bits para direccionar la memoria, por lo que un puntero tendrá 8 bytes, el doble que un entero de 4 bytes.
string
- Podríamos tener una variable
string spara un nombre comoEMMA, y ser capaces de acceder a cada caracter cons[0]y así sucesivamente:![Cajas una al lado de la otra, que contienen: E etiquetado como s[0], M etiquetado como s[1], M etiquetado como s[2], A etiquetado como s[3], \0 etiquetado como s[4]](https://cs50.harvard.edu/x/2020/notes/4/s_array.png)
- Pero resulta que cada caracter se almacena en la memoria en un byte con alguna dirección, y
ses en realidad solo un puntero con la dirección del primer caracter: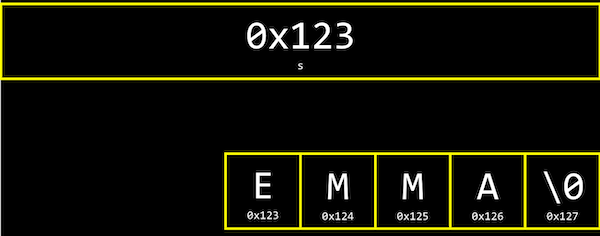
- Y dado que
ses solo un puntero al principio, solo\0indica el final de la cadena. - De hecho, la biblioteca CS50 define un
stringcontypedef char *string, que solo dice que queremos nombrar un nuevo tipo,string, comochar *, o un puntero a un caracter. -
Imprimamos una cadena:
#include <cs50.h> #include <stdio.h> int main(void) { string s = "EMMA"; printf("%s\n", s); } -
Esto es familiar, pero podemos decir simplemente:
#include <stdio.h> int main(void) { char *s = "EMMA"; printf("%s\n", s); }- Esto también imprimirá
EMMA.
- Esto también imprimirá
-
Con
printf("%p\n", s);, podemos imprimirscomo su valor como puntero, como0x42ab52. (printfsabe ir a la dirección e imprimir la cadena completa cuando usamos%sy pasamoss, aunquessolo apunta al primer caracter.) - También podemos probar
printf("%p\n", &s[0]);, que es la dirección del primer caracter des, y es exactamente lo mismo que imprimirs. E imprimir&s[1],&s[2]y&s[3]nos da las direcciones que son los siguientes caracteres en la memoria después de&s[0], como0x42ab53,0x42ab54y0x42ab55, exactamente un byte tras otro. - Y finalmente, si intentamos
printf("%c\n", *s);, obtenemos un solo caracterE, ya que vamos a la dirección contenida ens, que tiene el primer caracter de la cadena. - De hecho,
s[0],s[1]ys[2]en realidad se asignan directamente a*s,*(s+1)y*(s+2), ya que cada uno de los caracteres siguientes están solo en la dirección del siguiente byte.
Comparar y copiar
-
Veamos
compare0:#include <cs50.h> #include <stdio.h> int main(void) { // Obtener dos enteros int i = get_int("i: "); int j = get_int("j: "); // Comparar enteros if (i == j) { printf("Iguales\n"); } else { printf("Diferentes\n"); } }- Podemos compilar y ejecutar esto, y nuestro programa funciona como esperaríamos, con los mismos valores de los dos enteros dando “Iguales” y valores diferentes “Diferentes”.
-
En
compare1, vemos que los mismos valores de cadena están causando que nuestro programa imprima “Diferentes”:#include <cs50.h> #include <stdio.h> int main(void) { // Obtener dos cadenas string s = get_string("s: "); string t = get_string("t: "); // Comparar direcciones de las cadenas if (s == t) { printf("Iguales\n"); } else { printf("Diferentes\n"); } }- Dado lo que ahora sabemos sobre las cadenas, esto tiene sentido porque cada variable “cadena” está apuntando a una ubicación diferente en la memoria, donde se almacena el primer carácter de cada cadena. Así que, aunque los valores de las cadenas sean iguales, esto siempre imprimirá “Diferentes”.
- Por ejemplo, nuestra primera cadena podría estar en la dirección 0x123, nuestra segunda podría estar en 0x456, y
sserá0x123ytserá0x456, por lo que esos valores serán diferentes. - Y
get_string, durante todo este tiempo, ha estado devolviendo solo unchar *, o un puntero al primer carácter de una cadena del usuario.
-
Ahora intentemos copiar una cadena:
#include <cs50.h> #include <ctype.h> #include <stdio.h> int main(void) { string s = get_string("s: "); string t = s; t[0] = toupper(t[0]); // Imprimir cadena dos veces printf("s: %s\n", s); printf("t: %s\n", t); }- Obtenemos una cadena
s, y copiamos el valor desent. Luego, capitalizamos la primera letra ent. - Pero cuando ejecutamos nuestro programa, vemos que tanto
scomotestán ahora capitalizados. - Dado que establecimos
syten los mismos valores, en realidad son punteros al mismo carácter, ¡y por eso capitalizamos el mismo carácter!
- Obtenemos una cadena
-
Para hacer una copia real de una cadena, debemos hacer un poco más de trabajo:
#include <cs50.h> #include <ctype.h> #include <stdio.h> #include <string.h> int main(void) { char *s = get_string("s: "); char *t = malloc(strlen(s) + 1); for (int i = 0, n = strlen(s); i < n + 1; i++) { t[i] = s[i]; } t[0] = toupper(t[0]); printf("s: %s\n", s); printf("t: %s\n", t); }- Creamos una nueva variable,
t, del tipochar *, conchar *t. Ahora, queremos apuntarla a un nuevo bloque de memoria lo suficientemente grande como para almacenar la copia de la cadena. Conmalloc, podemos asignar algunos bytes en memoria (que no estén ya usados para almacenar otros valores), y pasamos el número de bytes que queremos. Ya sabemos la longitud des, así que agregamos 1 para el carácter nulo terminador. Así que, nuestra línea final de código eschar *t = malloc(strlen(s) + 1);. - Luego, copiamos cada carácter, uno a la vez, y ahora podemos capitalizar solo la primera letra de
t. Y usamosi < n + 1, ya que en realidad queremos ir hastan, para asegurarnos de copiar el carácter terminador en la cadena. - De hecho, también podemos usar la función de biblioteca
strcpyconstrcpy(t, s)en lugar de nuestro bucle, para copiar la cadenasent. Para ser claros, el concepto de “cadena” es del lenguaje C y está bien soportado; las únicas ruedas de entrenamiento de CS50 son el tipostringen lugar dechar *, y la funciónget_string.
- Creamos una nueva variable,
-
Si no copiamos el carácter nulo terminador,
\0, y tratamos de imprimir nuestra cadenat,printfcontinuará e imprimirá los valores desconocidos o basura que tenemos en memoria, hasta que llegue a un\0, o se bloquee por completo, ¡ya que nuestro programa podría terminar intentando leer memoria que no le pertenece!
valgrind
- Resulta que, luego de terminar con la memoria que asignamos con
malloc, debemos llamar afree(como enfree(t)), que le dice a nuestra computadora que esos bytes ya no son útiles para nuestro programa, de manera que esos bytes en la memoria pueden reutilizarse. - Si siguiéramos ejecutando nuestro programa y asignando memoria con
malloc, pero nunca liberando la memoria luego de terminar de usarla, tendríamos una fuga de memoria, que ralentizará nuestra computadora y utilizará cada vez más más hasta que la computadora se quede sin memoria. valgrindes una herramienta de línea de comando que podemos usar para ejecutar nuestro programa y ver si tiene fugas de memoria. Podemos ejecutar valgrind en nuestro programa anterior conhelp50 valgrind ./copyy ver, en el mensaje de error, que en la línea 10 asignamos memoria que nunca liberamos (o "perdimos").- De modo que al final, podemos agregar una línea
free(t), que no cambiará la manera en que se ejecuta nuestro programa, pero tampoco arrojará errores en valgrind. -
Echemos un vistazo a
memory.c:// http://valgrind.org/docs/manual/quick-start.html#quick-start.prepare #include <stdlib.h> void f(void) { int *x = malloc(10 * sizeof(int)); x[10] = 0; } int main(void) { f(); return 0; }- Este es un ejemplo de la documentación de valgrind (valgrind es una herramienta real, mientras que help50 fue escrita específicamente para ayudarnos en este curso).
- La función
fasigna memoria suficiente para 10 enteros, y almacena la dirección en un puntero llamadox. Luego intentamos establecer el valor 11 dexconx[10]en0, que se sale del arreglo de memoria que asignamos para nuestro programa. Esto se llama desbordamiento de búfer, donde nos salimos de los límites de nuestro búfer, o arreglo, y entramos en una memoria desconocida.
-
valgrind también nos dirá que hay una "escritura no válida de tamaño 4" para la línea 8, donde de hecho estamos intentando cambiar el valor de un entero (de tamaño 4 bytes).
- ¡Y durante todo este tiempo, la biblioteca CS50 ha estado liberando memoria que asignó en
get_string, cuando nuestro programa finaliza!
Intercambio
- Tenemos dos bebidas de color, morada y verde, cada una en una taza. Queremos intercambiar las bebidas entre ambas tazas, pero no podemos hacerlo sin una tercera taza para verter primero una de las bebidas.
-
Ahora, digamos que queremos intercambiar los valores de dos enteros.
void swap(int a, int b) { int tmp = a; a = b; b = tmp; }- Con una tercera variable para usarla como espacio de almacenamiento temporal, podemos hacer esto fácilmente, poniendo
aentmpy luegobenay, por último, el valor original dea, ahora entmp, enb.
- Con una tercera variable para usarla como espacio de almacenamiento temporal, podemos hacer esto fácilmente, poniendo
-
Pero si intentamos usar esa función en un programa, no vemos ningún cambio:
#include <stdio.h> void swap(int a, int b); int main(void) { int x = 1; int y = 2; printf("x es %i, y es %i\n", x, y); swap(x, y); printf("x es %i, y es %i\n", x, y); } void swap(int a, int b) { int tmp = a; a = b; b = tmp; } -
Resulta que la función
swaprecibe sus propias variables,aybcuando se pasan, que son copias dexey, por lo que cambiar esos valores no cambiaxeyen la funciónmain.
Diseño de memoria
- Dentro de la memoria de nuestra computadora, los diferentes tipos de datos que hay que almacenar para nuestro programa se organizan en diferentes secciones:

- La sección del código de máquina contiene el código binario de nuestro programa compilado. Cuando ejecutamos nuestro programa, ese código se carga en la "cima" de la memoria.
- Las variables globales son variables globales que declaramos en nuestro programa u otras variables compartidas a las que todo nuestro programa puede acceder.
- La sección del heap es un área vacía de la que
mallocpuede obtener memoria libre para que la use nuestro programa. - La sección de la pila es usada por las funciones de nuestro programa a medida que son llamadas. Por ejemplo, nuestra función
mainestá en la base de la pila y tiene las variables localesxey. La funciónswap, cuando es llamada, tiene su propio marco, o porción, de memoria que está encima del demain, con las variables localesa,bytmp:

- Una vez que la función
swapregresa, la memoria que usaba se libera para la siguiente llamada a la función y perdemos todo lo que hicimos, excepto los valores de retorno, y nuestro programa regresa a la función que llamó aswap. - Así, al pasar las direcciones de
xeydesdemainaswap, podemos cambiar los valores dexey:
- Una vez que la función
-
Al pasar la dirección de
xey, nuestra funciónswappuede funcionar:#include <stdio.h> void swap(int *a, int *b); int main(void) { int x = 1; int y = 2; printf("x es %i, y es %i\n", x, y); swap(&x, &y); printf("x es %i, y es %i\n", x, y); } void swap(int *a, int *b) { int tmp = *a; *a = *b; *b = tmp; }- Las direcciones de
xeyse pasan desdemainaswap, y usamos la sintaxisint *apara declarar que nuestra funciónswaprecibe punteros. Guardamos el valor dexentmpsiguiendo el punteroay luego tomamos el valor deysiguiendo el punteroby guardamos ese valor en la ubicación a la que apuntaa(x). Finalmente, guardamos el valor detmpen la ubicación a la que apuntab(y) y terminamos.
- Las direcciones de
-
Si llamamos a
mallocdemasiadas veces, tendremos un desbordamiento del heap, donde terminamos yendo más allá de nuestro heap. O si tenemos demasiadas funciones siendo llamadas, tendremos un desbordamiento de pila, donde nuestra pila también tiene demasiados marcos de memoria asignados. Y estos dos tipos de desbordamiento se conocen generalmente como desbordamientos de búfer, después de los cuales nuestro programa (o toda la computadora) podría fallar.
get_int
-
Podemos implementar
get_intnosotros mismos con una función de la biblioteca C,scanf:#include <stdio.h> int main(void) { int x; printf("x: "); scanf("%i", &x); printf("x: %i\n", x); }scanftoma un formato,%i, de modo que la entrada es “escaneada” para ese formato y la dirección en memoria donde queremos que vaya esa entrada. Peroscanfno tiene mucha comprobación de errores, por lo que es posible que no obtengamos un entero.
-
Podemos intentar obtener una cadena de la misma manera:
#include <stdio.h> int main(void) { char *s = NULL; printf("s: "); scanf("%s", s); printf("s: %s\n", s); }- Pero en realidad no hemos asignado memoria para
s(sesNULLo no apunta a nada), por lo que es posible que queramos llamar achar s[5]para asignar un arreglo de 5 caracteres para nuestra cadena. Entonces,sserá tratado como un puntero enscanfyprintf. - Ahora, si el usuario ingresa una cadena de longitud 4 o menos, nuestro programa funcionará de forma segura. Pero si el usuario ingresa una cadena más larga,
scanfpodría estar tratando de escribir después del final de nuestra matriz en una memoria desconocida, lo que provoca que nuestro programa se bloquee.
- Pero en realidad no hemos asignado memoria para
Archivos
-
Con la capacidad de usar punteros, también podemos abrir archivos:
#include <cs50.h> #include <stdio.h> #include <string.h> int main(void) { // Abrir el archivo FILE *file = fopen("phonebook.csv", "a"); // Obtener cadenas del usuario char *name = get_string("Name: "); char *number = get_string("Number: "); // Imprimir (escribir) cadenas en el archivo fprintf(file, "%s,%s\n", name, number); // Cerrar el archivo fclose(file); }fopenes una nueva función que podemos utilizar para abrir un archivo. Devolverá un puntero a un nuevo tipo,FILE, desde el que podemos leer y escribir. El primer argumento es el nombre del archivo y el segundo argumento es el modo en el que queremos abrir el archivo (rpara leer,wpara escribir yapara añadir o agregar).- Después de obtener algunas cadenas, podemos utilizar
fprintfpara imprimir en un archivo. - Finalmente, cerramos el archivo con
fclose.
-
Ahora podemos crear nuestros propios archivos CSV, archivos de valores separados por comas (como una minihoja de cálculo), mediante programación.
JPEG
-
También podemos escribir un programa que abra un archivo y nos diga si es un archivo JPEG (imagen):
#include <stdio.h> int main(int argc, char *argv[]) { // Revisar el uso if (argc != 2) { return 1; } // Abrir archivo FILE *archivo = fopen(argv[1], "r"); if (!archivo) { return 1; } // Leer los primeros tres bytes unsigned char bytes[3]; fread(bytes, 3, 1, archivo); // Revisar los primeros tres bytes if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff) { printf("Quizás\n"); } else { printf("No\n"); } // Cerrar archivo fclose(archivo); }- Ahora, si ejecutamos este programa con
./jpeg brian.jpg, nuestro programa tratará de abrir el archivo que especificamos (revisando que de hecho obtengamos un archivo no NULL), y leer los primeros tres bytes del archivo confread. - Podemos comparar los primeros tres bytes (en hexadecimal) con los tres bytes requeridos para iniciar un archivo JPEG. Si son los mismos, es probable que nuestro archivo sea un archivo JPEG (aunque otros tipos de archivos también podrían comenzar con esos bytes). Pero si no son iguales, sabemos que definitivamente no es un archivo JPEG.
- Ahora, si ejecutamos este programa con
-
¡Podemos usar estas habilidades para leer y escribir archivos, en particular imágenes, y modificarlos cambiando los bytes en ellos, en el conjunto de problemas de esta semana!