Lectura 7
Hojas de cálculo
- La mayoría de nosotros estamos familiarizados con las hojas de cálculo, filas de datos, donde cada columna en una fila contiene una información diferente que, de alguna manera, se relaciona entre sí.
- Una base de datos es una aplicación que puede almacenar datos, y podemos considerar a Google Sheets como una de esas aplicaciones.
- Por ejemplo, creamos un formulario de Google para preguntarles a los estudiantes cuál era su programa de televisión favorito y el género del mismo. Revisamos las respuestas y vemos que la hoja de cálculo tiene tres columnas: "Fecha y hora", "Título" y "Géneros":
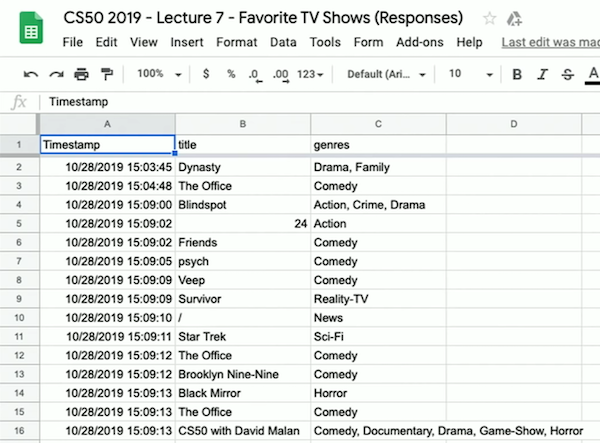
- Podemos descargar un archivo CSV de la hoja de cálculo con "Archivo > Descargar", subirlo a nuestro IDE, y ver que es un archivo de texto con valores separados por comas que coinciden con los datos de la hoja de cálculo.
-
Escribiremos
favorites.py:import csv with open("CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv", "r") as file: reader = csv.DictReader(file) for row in reader: print(row["title"]) -
Vamos a abrir el archivo y asegurarnos de poder obtener el título de cada fila.
-
Ahora podemos usar un diccionario para contar cuántas veces hemos visto cada título, donde las claves son los títulos y los valores para cada clave son un entero, que rastrea cuántas veces hemos visto ese título:
import csv counts = {} with open("CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv", "r") as file: reader = csv.DictReader(file) for row in reader: title = row["title"] if title in counts: counts[title] += 1 else: counts[title] = 1 for title, count in counts.items(): print(title, count, sep=" | ") -
En cada fila, podemos obtener el
títuloconrow["title"]. - Aquí, si ya hemos visto el título antes (está en
counts), solo podemos sumar 1 al valor. De lo contrario, necesitamos establecer el valor inicial en 1. -
Finalmente, podemos imprimir las claves y los valores de nuestro diccionario con un separador, para facilitar un poco su lectura.
-
Podemos cambiar la forma en la que hacemos la iteración a
for title, count in sorted(counts.items()):y veremos nuestro diccionario ordenado por claves, alfabéticamente. -
Pero podemos ordenar por los pares clave-valor en el diccionario con:
def f(item): return item[1] for title, count in sorted(counts.items(), key=f, reverse=True): -
Definimos una función,
f, que solo devuelve el valor delítemen el diccionario conitem[1]. La funciónsorted, a su vez, puede usar eso como la clave para ordenar los elementos del diccionario. Y también pasaremosreverse=Truepara ordenar de mayor a menor, en lugar de menor a mayor. -
De hecho, podemos definir nuestra función en la misma línea, con esta sintaxis:
for title, count in sorted(counts.items(), key=lambda item: item[1], reverse=True): -
Pasamos un lambda, o función anónima, como clave, que toma el
ítemy devuelveitem[1]. -
Finalmente, podemos poner todos los títulos en minúsculas con
title = row["title"].lower(), por lo que nuestros recuentos pueden ser un poco más precisos, incluso si los nombres no fueron escritos exactamente de la misma manera.
SQL
- Vamos a ver un nuevo programa en nuestra ventana de terminal,
sqlite3, un programa de línea de comandos que nos permite utilizar otro lenguaje, SQL (pronunciado como "secuela"). -
Ejecutaremos algunos comandos para crear una nueva base de datos llamada
favorites.dbe importar nuestro archivo CSV en una tabla llamada "favorites":~/ $ sqlite3 favorites.db SQLite version 3.22.0 2018-01-22 18:45:57 Introduzca ".help" para obtener sugerencias de uso. sqlite> .mode csv sqlite> .import "CS50 2019 - Lección 7 - Programas de TV favoritos (respuestas) - Respuestas del formulario 1.csv" favorites -
Vemos un
favorites.dben nuestro IDE después de ejecutar esto, y ahora podemos usar SQL para interactuar con nuestros datos:sqlite> SELECT title FROM favorites; title Dynasty The Office Blindspot 24 Friends psych Veep Survivor ... -
Incluso podemos ordenar nuestros resultados:
sqlite> SELECT title FROM favorites ORDER BY title; title / 24 9009 Adventure Time Airplane Repo Always Sunny Ancient Aliens ... -
Y obtener un recuento del número de veces que aparece cada título:
sqlite> SELECT title, COUNT(title) FROM favorites GROUP BY title; title | COUNT(title) / | 1 24 | 1 9009 | 1 Adventure Time | 1 Airplane Repo | 1 Always Sunny | 1 Ancient Aliens | 1 ... -
Incluso podemos establecer el recuento de cada título a una nueva variable,
n, y ordenar nuestros resultados por eso, en orden descendente. Luego, podemos ver los primeros 10 resultados conLIMIT 10:sqlite> SELECT title, COUNT(title) AS n FROM favorites GROUP BY title ORDER BY n DESC LIMIT 10; title | n The Office | 30 Friends | 20 Game of Thrones | 20 Breaking Bad | 14 Black Mirror | 9 Rick and Morty | 9 Brooklyn Nine-Nine | 5 Game of thrones | 5 No | 5 Prison Break | 5 -
SQL es un lenguaje que nos permite trabajar con una base de datos relacional, una aplicación que nos permite almacenar datos y trabajar con ellos más rápidamente que con un CSV.
-
Con
.schema, podemos ver cómo se crea el formato de la tabla para nuestros datos:sqlite> .schema CREATE TABLE favoritos( "Fecha" TEXT, "título" TEXT, "géneros" TEXT ); -
Resulta que, al trabajar con datos, solo necesitamos cuatro operaciones:
CREARLEERACTUALIZARELIMINAR
- En SQL, los comandos para realizar cada una de estas operaciones son:
INSERTARSELECCIONARACTUALIZARELIMINAR
- Primero, necesitaremos insertar una tabla con el comando
CREATE TABLE table (column type, ...);. - SQL también tiene sus propios tipos de datos para optimizar la cantidad de espacio utilizado para almacenar datos:
BLOB, para “objeto binario grande”, datos binarios sin procesar que pueden representar archivosINTEGERsmallintintegerbigint
NUMERICbooleandatedatetimenumeric(scale,precision), que resuelve la imprecisión de punto flotante mediante el uso de tantos bits como sea necesario, para cada dígito antes y después del punto decimaltimetimestamp
REALreal, para valores de punto flotantedouble precision, con más bits
TEXTchar(n), para un número exacto de caracteresvarchar(n), para un número variable de caracteres, hasta cierto límitetext
- SQLite es una aplicación de base de datos que soporta SQL, y hay muchas empresas con aplicaciones de servidor que soportan SQL, incluyendo Oracle Database, MySQL, PostgreSQL, MariaDB y Microsoft Access.
- Después de insertar valores, también podemos usar funciones para realizar cálculos:
AVGCOUNTDISTINCT, para obtener valores distintos sin duplicadosMAXMIN- …
- También hay otras operaciones que podemos combinar según sea necesario:
WHERE, coincidencia en alguna condición estrictaLIKE, coincidencia en subcadenas para textoLIMITGROUP BYORDER BYJOIN, combinando datos de varias tablas
- Podemos actualizar datos con
UPDATE table SET column=value WHERE condition;, que podría incluir 0, 1 o más filas según nuestra condición. Por ejemplo, podríamos decirUPDATE favoritos SET título = "The Office" WHERE título LIKE "%office", y eso establecerá todas las filas con el título que contenga "office" a "The Office" para que podamos hacerlas consistentes. - Y podemos eliminar filas coincidentes con
DELETE FROM table WHERE condition;, como enDELETE FROM favoritos WHERE título = "Friends";. - Incluso podemos eliminar una tabla completa con otro comando,
DROP.
IMDb
- IMDb, o "Base de Datos de Películas en Internet", tiene conjuntos de datos disponibles para descargar como archivos TSV (valores separados por tabulaciones).
- Por ejemplo, podemos descargar
title.basics.tsv.gz, que contendrá datos básicos sobre los títulos:tconst, un identificador único para cada título, comott4786824titleType, el tipo de título, comotvSeriesprimaryTitle, el título principal utilizado, comoThe CrownstartYear, el año en que se lanzó un título, como2016genres, una lista de géneros separados por comas, comoDrama,Historia
- Echamos un vistazo a
title.basics.tsvdespués de haberlo descomprimido y vemos que las primeras filas son de hecho los encabezados que esperábamos y cada fila tiene valores separados por tabulaciones. Pero el archivo tiene más de 6 millones de filas, por lo que incluso buscar un valor lleva un momento. - Descargaremos el archivo en nuestro IDE con
wgety luegogunzippara descomprimirlo. Pero nuestro IDE no tiene suficiente espacio, por lo que en su lugar usaremos la terminal de nuestra Mac. -
Escribiremos
import.pypara leer el archivo:import csv # Abrir el archivo TSV para lectura with open("title.basics.tsv", "r") as titles: # Puesto que el archivo es un archivo TSV, podemos utilizar el lector CSV y cambiar # el separador a una tabulación. reader = csv.DictReader(titles, delimiter="\t") # Abrir un nuevo archivo CSV para escritura with open("shows0.csv", "w") as shows: # Crear escritor writer = csv.writer(shows) # Escribir el encabezado de las columnas que queremos writer.writerow(["tconst", "primaryTitle", "startYear", "genres"]) # Iterar sobre el archivo TSV for row in reader: # Si es un programa de televisión no adulto if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Escribir fila writer.writerow([row["tconst"], row["primaryTitle"], row["startYear"], row["genres"]]) -
Ahora, podemos abrir
shows0.csvy ver un conjunto de datos más pequeño. Pero resulta que, para algunas de las filas,startYeartiene un valor de\N, y ese es un valor especial de IMDb cuando se quieren representar valores que faltan. Así que podemos filtrar esos valores y convertirstartYeara un entero para filtrar los programas posteriores a 1970:... # Si el año no falta (también necesitamos escapar la barra invertida) if row["startYear"] != "\\N": # Si es a partir de 1970 if int(row["startYear"]) >= 1970: # Escribir fila writer.writerow([row["tconst"], row["primaryTitle"], row["startYear"], row["genres"]]) -
Podemos escribir un programa para buscar un título en particular:
import csv # Solicitar el título al usuario title = input("Título: ") # Abrir el archivo CSV with open("shows2.csv", "r") as input: # Crear DictReader reader = csv.DictReader(input) # Iterar sobre el archivo CSV for row in reader: # Buscar el título if title.lower() == row["primaryTitle"].lower(): print(row["primaryTitle"], row["startYear"], row["genres"], sep=" | ")- Podemos ejecutar este programa y ver nuestros resultados, pero podemos observar cómo SQL puede realizar un mejor trabajo.
-
En Python, podemos conectarnos a una base de datos SQL y leer nuestro archivo en ella una vez, para poder hacer muchas consultas sin escribir nuevos programas y sin tener que leer todo el archivo cada vez.
-
Hagamos esto más fácilmente con la biblioteca CS50:
import cs50 import csv # Crear la base de datos abriendo y cerrando primero un archivo vacío open(f"shows3.db", "w").close() db = cs50.SQL("sqlite:///shows3.db") # Crear una tabla llamada `shows`, y especificar las columnas que queremos, # todas las cuales serán de texto excepto `startYear` db.execute("CREATE TABLE shows (tconst TEXT, primaryTitle TEXT, startYear NUMERIC, genres TEXT)") # Abrir el archivo TSV # https://datasets.imdbws.com/title.basics.tsv.gz with open("title.basics.tsv", "r") as titles: # Crear DictReader reader = csv.DictReader(titles, delimiter="\t") # Iterar sobre el archivo TSV for row in reader: # Si es un programa de televisión que no es para adultos if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Si el año no falta if row["startYear"] != "\\N": # Si es a partir de 1970 startYear = int(row["startYear"]) if startYear >= 1970: # Insertar el programa sustituyendo valores en cada marcador de posición ? db.execute("INSERT INTO shows (tconst, primaryTitle, startYear, genres) VALUES(?, ?, ?, ?)", row["tconst"], row["primaryTitle"], startYear, genres) -
Ahora podemos ejecutar
sqlite3 shows3.dby ejecutar comandos como antes, comoSELECT * FROM shows LIMIT 10;. - Con
SELECT COUNT(*) FROM shows;podemos ver que hay más de 150,000 programas en nuestra tabla, y conSELECT COUNT(*) FROM shows WHERE startYear = 2019;, vemos que hubo más de 6000 este año.
Tablas múltiples
-
Pero cada una de las filas solo tendrá una columna para el género y los valores son múltiples géneros agrupados. Así que podemos volver a nuestro programa de importación y añadir otra tabla:
import cs50 import csv # Crear base de datos open(f"shows4.db", "w").close() db = cs50.SQL("sqlite:///shows4.db") # Crear tablas db.execute("CREATE TABLE shows (id INT, title TEXT, year NUMERIC, PRIMARY KEY(id))") # La tabla `genres` tendrá una columna llamada `show_id` que hace referencia # a la tabla `shows` anterior db.execute("CREATE TABLE genres (show_id INT, genre TEXT, FOREIGN KEY(show_id) REFERENCES shows(id))") # Abrir archivo TSV # https://datasets.imdbws.com/title.basics.tsv.gz with open("title.basics.tsv", "r") as titles: # Crear DictReader reader = csv.DictReader(titles, delimiter="\t") # Iterar sobre el archivo TSV for row in reader: # Si no es un programa de televisión para adultos if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Si el año no falta if row["startYear"] != "\\N": # Si es desde 1970 startYear = int(row["startYear"]) if startYear >= 1970: # Recortar el prefijo de tconst id = int(row["tconst"][2:]) # Insertar programa db.execute("INSERT INTO shows (id, title, year) VALUES(?, ?, ?)", id, row["primaryTitle"], startYear) # Insertar géneros if row["genres"] != "\\N": for genre in row["genres"].split(","): db.execute("INSERT INTO genres (show_id, genre) VALUES(?, ?)", id, genre) -
Así que ahora nuestra tabla
showya no tiene una columnagenres, sino que tenemos una tablagenrescon cada fila que representa un programa y un género asociado. Ahora, un programa particular puede tener múltiples géneros que podemos buscar, y podemos obtener otros datos sobre el programa de la tablashowsdado su ID. -
De hecho, podemos combinar ambas tablas con
SELECT * FROM shows WHERE id IN (SELECT show_id FROM genres WHERE genre = "Comedy") AND year = 2019;. Estamos filtrando nuestra tablashowspor identificadores donde la ID en la tablagenrestiene un valor de "Comedy" para la columnagenrey tiene el valor de 2019 para la columnayear. - Nuestras tablas se ven así:
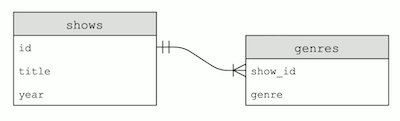
- Dado que la ID en la tabla
genreprocede de la tablashows, la llamamosshow_id. La flecha indica que una única ID de show puede tener muchas filas coincidentes en la tablagenres.
- Dado que la ID en la tabla
- Vemos que algunos conjuntos de datos de IMDb, como
title.principals.tsv, solo tienen identificadores para determinadas columnas que tendremos que buscar en otras tablas. - Al leer las descripciones de cada tabla, podemos ver que todos los datos se pueden utilizar para construir estas tablas:
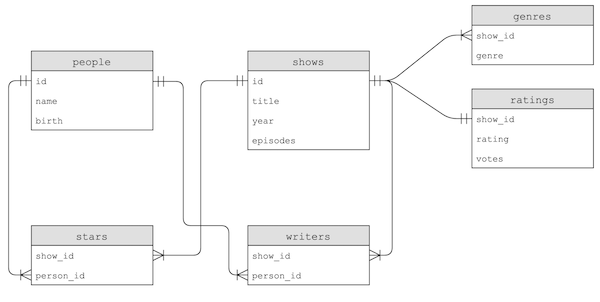
- Advierte que, por ejemplo, el nombre de una persona también podría copiarse a las tablas
starsowriters, pero en su lugar solo se utiliza elperson_idpara vincular a los datos en la tablapeople. De esta forma, solo necesitamos actualizar el nombre en un lugar si necesitamos realizar un cambio.
- Advierte que, por ejemplo, el nombre de una persona también podría copiarse a las tablas
- Abriremos una base de datos,
shows.db, con estas tablas para ver más ejemplos. - Descargaremos un programa llamado DB Browser for SQLite, que tendrá una interfaz gráfica de usuario para examinar nuestras tablas y datos. Podemos utilizar la pestaña "Execute SQL" (Ejecutar SQL) para ejecutar SQL directamente en el programa también.
- Podemos ejecutar
SELECT * FROM shows JOIN genres ON show.id = genres.show_id;para unir dos tablas haciendo coincidir las identificaciones de las columnas que especificamos. Luego, obtendremos una tabla más amplia con columnas de cada una de esas dos tablas. - Podemos tomar la ID de una persona y encontrarla en shows con
SELECT * FROM stars WHERE person_id = 1122;, pero podemos hacer una consulta dentro de nuestra consulta conSELECT show_id FROM stars WHERE person_id = (SELECT id FROM people WHERE name = "Ellen DeGeneres");. - Esto nos devuelve el
show_id, por lo que para obtener los datos del programa, podemos ejecutar:SELECT * FROM shows WHERE id IN (...);con...siendo la consulta anterior. -
Podemos obtener los mismos resultados con:
SELECT title FROM people JOIN stars ON people.id = stars.person_id JOIN shows ON stars.show_id = shows.id WHERE name = "Ellen DeGeneres"- Unimos la tabla
peoplecon la tablastarsy luego con la tablashowsespecificando columnas que deberían coincidir entre las tablas, y luego seleccionando solotitlecon un filtro en el nombre. - Pero ahora podemos también seleccionar otros campos de nuestras tablas combinadas.
- Unimos la tabla
-
Resulta que podemos especificar columnas de nuestras tablas para que sean tipos especiales, tales como:
PRIMARY KEY(clave principal), que se utiliza como identificador principal para una filaFOREIGN KEY(clave externa), que apunta a una fila en otra tablaUNIQUE(único), lo que significa que tiene que ser único en esta tablaINDEX(índice), que pide a nuestra base de datos que cree un índice para consultar más rápidamente según esta columna. Un índice es una estructura de datos como un árbol, que nos ayuda a buscar valores.
- Podemos crear un índice con
CREATE INDEX person_index ON stars (person_id);. Luego, la columnaperson_idtendrá un índice llamadoperson_index. Con los índices correctos, nuestra consulta de unión es cientos de veces más rápida.
Problemas
- Un problema con bases de datos son las condiciones de carrera, donde la asociación temporal de dos acciones o eventos provoca un comportamiento inesperado.
- Por ejemplo, considera a dos compañeros de cuarto y un refrigerador compartido en su dormitorio. El primer compañero de cuarto llega a casa y ve que no hay leche en el refrigerador. Entonces, el primero sale a la tienda a comprar leche, y mientras está en la tienda, el segundo compañero de cuarto llega a casa, ve que no hay leche y se va a otra tienda a comprar leche. Más tarde, habrá dos jarras de leche en el refrigerador. Al dejar una nota, podemos resolver este problema. Incluso podemos cerrar el refrigerador para que nuestro compañero de cuarto no pueda verificar si hay leche, hasta que regresemos.
-
Esto puede suceder en nuestra base de datos si tenemos algo como esto:
rows = db.execute("SELECT likes FROM posts WHERE id=?", id); likes = rows[0]["likes"] db.execute("UPDATE posts SET likes = ?", likes + 1);- Primero, obtenemos el número de me gusta en una publicación con una ID determinada. Luego, configuramos el número de me gusta en ese número más uno.
- Pero ahora, si tenemos dos servidores web diferentes que intentan agregar un me gusta, ambos podrían establecerlo en el mismo valor en lugar de agregar uno cada vez. Por ejemplo, si hay 2 me gusta, ambos servidores verificarán el número de me gusta, verán que hay 2 y establecerán el valor en 3. Entonces se perderán uno de los me gusta.
-
Para resolver esto, podemos utilizar transacciones, donde se garantiza que un conjunto de acciones ocurra juntas.
- Otro problema en SQL se denomina ataque de inyección SQL, donde un adversario puede ejecutar sus propios comandos en nuestra base de datos.
- Por ejemplo, alguien podría intentar escribir
malan@harvard.edu'--como su correo electrónico. Si tenemos una consulta SQL que es una string con formato (sin escape o sustituyendo caracteres peligrosos de la entrada), comof"SELECT * FROM users WHERE username = '{username}' AND password = '{password}'", entonces la consulta terminará siendof"SELECT * FROM users WHERE username = 'malan@harvard.edu'--' AND password = '{password}'", que en realidad seleccionará la fila dondeusername = 'malan@harvard.edu'y convertirá el resto de la línea en un comentario. Para evitar esto, deberíamos usar marcadores de posición?para que nuestra biblioteca SQL escape automáticamente las entradas del usuario.